


CBF
추천 알고리즘으로 가장 기본적인 형태이다. CBF(Contents Based Filtering)는 데이터가 가지는 속성(Content)를 기반으로 또 다른 유사한 데이터를 추천해주는 알고리즘이다. 이 때 유사함이란 특정한 유사도(similiarity)를 기준으로 측정된 거리를 말하며 가까운 거리일수록 추천할만한 유사 데이터라고 해석한다.
데이터 전처리
CBF 알고리즘의 특성 상 keyword 항목이 데이터 안에서 중복되는 횟수가 적은 경우에는 추천시스템의 성능이 매우 떨어질 수 있다. 예를 들면 대다수가 액션 장르인 영화 데이터셋에서 오컬트 장르의 영화를 추천받기 원하는 경우와 같다. 따라따라서 조금 더 상위 개념의 keyword인 카테고리(분야)를 추가하여 데이터 사이에 겹치는 keyword를 추가해주었다.
오컬트, 호러, 슬래셔와 같은 하위 장르들의 키워드가 있다면 '공포'라는 상위 개념의 키워드를 각각 추가하여 유사도(컨텐츠 사이의 거리)를 좀 더 높인 것과 같다.
# module & library
import pandas as pd
df_best = pd.read_excel('kyobo_best_all.xlsx')
df_keyword = pd.read_excel('book_keyword.xlsx')
# category 추가
df_CBF = df_keyword.join(df_best.set_index('도서명')['카테고리'], on='title')
df_CBF.rename(columns={'카테고리':'category'}, inplace=True)
# 카테고리와 장르 합친 새로운 컬럼 생성
df_CBF["keyword2"] = df_CBF['category'] + " " + df_CBF["keyword"]
# 중복데이터 제거
df_CBF =df_CBF.drop_duplicates(subset="title", keep='first', inplace=False, ignore_index=False)
df_CBF.reset_index(drop=True, inplace=True)
df_CBF.info()
df_CBF.head()
추천 함수 설정
# count 기반 피처 벡터화 (유사도 측정 기준)
from sklearn.feature_extraction.text import CountVectorizer
# 가중평점 반영 안한 추천시스템
def find_sim_book_ver1(df_CBF, sorted_ind, title_name, top_n=10):
# 인자로 입력된 movies_df DataFrame에서 'title' 컬럼이 입력된 title_name 값인 DataFrame추출
title_book = df_CBF[df_CBF['title'] == title_name]
# title_named을 가진 DataFrame의 index 객체를 ndarray로 반환하고
# sorted_ind 인자로 입력된 genre_sim_sorted_ind 객체에서 유사도 순으로 top_n 개의 index 추출
title_index = title_book.index.values
similar_indexes = sorted_ind[title_index, :(top_n)]
# 추출된 top_n index들 출력. top_n index는 2차원 데이터 임.
# dataframe에서 index로 사용하기 위해서 1차원 array로 변경
print(similar_indexes)
# 2차원 데이터를 1차원으로 변환
similar_indexes = similar_indexes.reshape(-1)
return df_CBF.iloc[similar_indexes]# 가중평점 반영한 추천시스템
def find_sim_book_ver2(df_CBF, sorted_ind, title_name, top_n=10):
title_book = df_CBF[df_CBF['title'] == title_name]
title_index = title_book.index.values
# top_n의 2배에 해당하는 쟝르 유사성이 높은 index 추출
similar_indexes = sorted_ind[title_index, :(top_n*1)]
similar_indexes = similar_indexes.reshape(-1)
# 기준 서적 index는 제외
similar_indexes = similar_indexes[similar_indexes != title_index]
# top_n의 2배에 해당하는 후보군에서 weighted_vote 높은 순으로 top_n 만큼 추출
return df_CBF.iloc[similar_indexes].sort_values('weighted_score', ascending=False)[:top_n]# CountVectorizer로 학습시켰더니 3096개의 책에 대한 22882개의 키워드의 "키워드 매트릭스"가 생성되었다.
count_vect = CountVectorizer(min_df=0, ngram_range=(1, 2)) # min_df: 단어장에 들어갈 최소빈도, ngram_range: 1 <= n <= 2 1단어, 2단어까지
genre_mat = count_vect.fit_transform(df_CBF['keyword']) # 키워드 기반학습
# CountVectorizer로 학습시켰더니 3096개의 책에 대한 24447개의 키워드의 "키워드 매트릭스"가 생성되었다.
count_vect = CountVectorizer(min_df=0, ngram_range=(1, 2)) # min_df: 단어장에 들어갈 최소빈도, ngram_range: 1 <= n <= 2 1단어, 2단어까지
genre_mat2 = count_vect.fit_transform(df_CBF['keyword2']) # 키워드 기반학습# 코사인 유사도에 의해 3096개 리스트에 대한 유사한 책 계산
from sklearn.metrics.pairwise import cosine_similarity
genre_sim = cosine_similarity(genre_mat, genre_mat)
genre_sim2 = cosine_similarity(genre_mat2, genre_mat2)
print(genre_sim.shape) # 키워드 기반
print(genre_sim[:10])
print(genre_sim2.shape) # 키워드2(카테고리+키워드) 기반
print(genre_sim2[:10])
# 0번째 책의 경우 유사도 순서 : 0번, 791번, 2615번.....
# 키워드 기반
genre_sim_sorted_ind = genre_sim.argsort()[:, ::-1] # ::-1 : 역순으로 정렬
print(genre_sim_sorted_ind[:5])
# 키워드2 기반
genre_sim_sorted_ind2 = genre_sim2.argsort()[:, ::-1] # ::-1 : 역순으로 정렬
print(genre_sim_sorted_ind[:5])
# 인자로 입력된 movies_df DataFrame에서 'title' 컬럼이 입력된 title_name 값인 DataFrame추출
title_book = df_CBF[df_CBF['title'] == '스포츠심리학의 정석(개정판)']
title_index = title_book.index.values
similar_indexes = genre_sim_sorted_ind[title_index, :10]
similar_indexes2 = genre_sim_sorted_ind2[title_index, :10]
print(similar_indexes)
print(similar_indexes2)
추천시스템
연금술사
similar_book = find_sim_book_ver1(df_CBF, genre_sim_sorted_ind, '연금술사', 10) # 책 제목 입력
similar_book[['title', 'score', 'total', 'keyword']]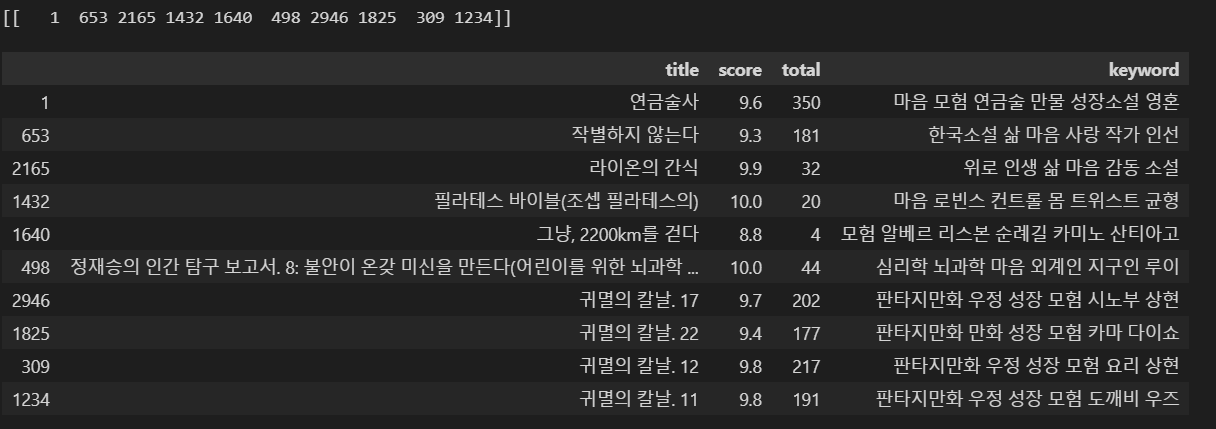
위의 추천 결과는 교보문고의 키워드를 그대로 사용한 결과이다. 이는 각 도서마다 키워드 선정이 지나치게 지엽적이기 때문에 개별 데이터 사이의 공통된 키워드가 적기 떄문잉다. 따라서 위에서 상기한 대로 공통 키워드로서 책 분야, 카테고리를 추가하였다.
similar_book = find_sim_book_ver1(df_CBF, genre_sim_sorted_ind2, '연금술사', 10) # 책 제목 입력
similar_book[['title', 'score', 'total', 'keyword2']]
소설이라는 공통 키워드를 추가한 형태가 훨씬 추천 성능이 좋음을 알 수 있다.
나는 나로 살기로 했다
similar_book = find_sim_book_ver1(df_CBF, genre_sim_sorted_ind2, '사피엔스', 10) # 책 제목 입력
similar_book[['title', 'score', 'total', 'keyword2']]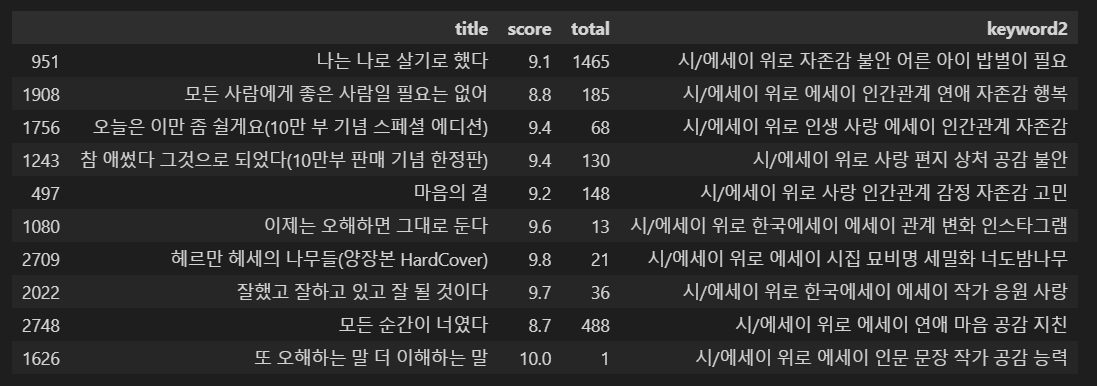
가중 평점 반영 (최종 버전)
바로 위의 결과에서 보면 스코어와 높지만 total, 즉 평점의 수가 너무 작아 신뢰하기 힘든 도서들이 많다. 따라서 리뷰의 횟수로 평점을 표준화한 가중평점을 지수를 새로 계산하여 좀 더 성능이 좋은 알고리즘으로 개선해본다.
# 상위 50%에 해당하는 vote_count를 최소 리뷰 횟수인 m으로 지정
C = df_CBF['score'].mean()
m = df_CBF['total'].quantile(0.5)
def weighted_vote_average(record): # 가중평균 함수
v = record['total']
R = record['score']
return ( (v/(v+m)) * R ) + ( (m/(m+v)) * C )# 가중평점(weighted_vote) 컬럼 추가
df_CBF['weighted_score'] = df_CBF.apply(weighted_vote_average, axis=1)
df_CBF.head(10)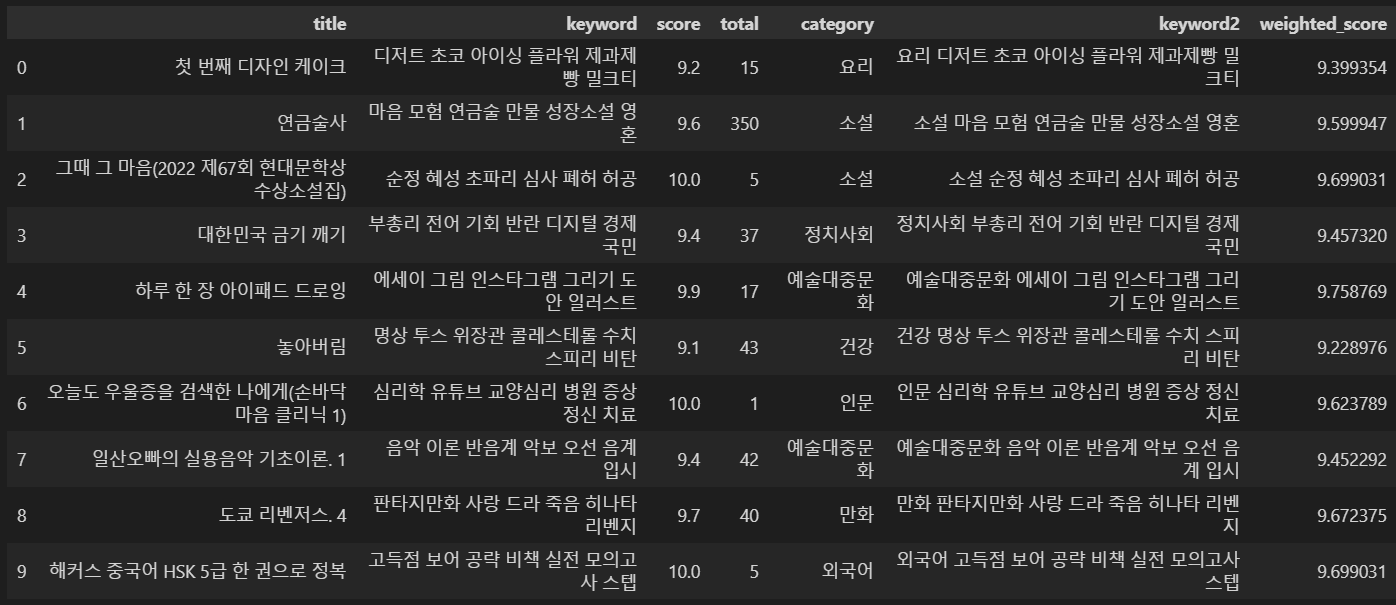
연금술사
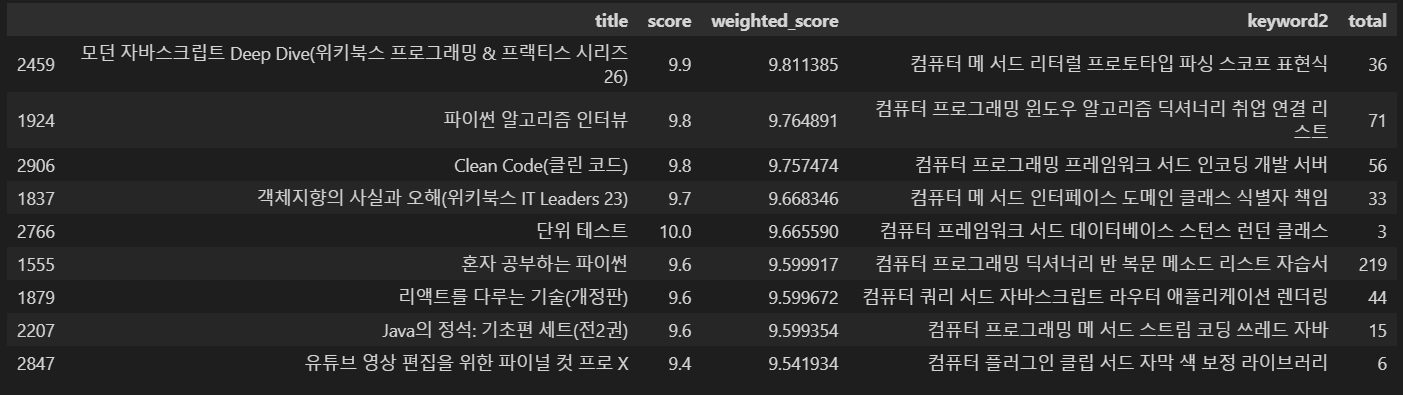
similar_movies = find_sim_book_ver2(df_CBF, genre_sim_sorted_ind2, '연금술사', 10)
similar_movies[['title', 'score', 'weighted_score', 'keyword2', 'total']]
나는 나로 살기로 했다

위의 추천 항목의 경우 평가 횟수가 1점이 10점인 항목이 추천되었는데 이는 가중평점 계산식의 미비함이 드러난 것이다. 최소 리뷰 갯수로 필터링을 한 뒤 가중평점을 적용하는 방식으로 접근하는 것이 좀 더 합리적인 방식이었다.
첫 번째 디자인 케이크

Do it! 점프 투 파이썬
'Jay's Project > 교보문고 책 추천시스템 구현' 카테고리의 다른 글
| [교보문고 베스트셀러 분석 / 추천시스템] 3. 베스트셀러 분석 (0) | 2022.07.23 |
|---|---|
| [교보문고 베스트셀러 분석 / 추천시스템] 2. 데이터 수집 (0) | 2022.07.21 |
| [교보문고 베스트셀러 분석 / 추천시스템] 1. 프로젝트 기획 (0) | 2022.07.21 |
| [교보문고 베스트셀러 분석 / 추천시스템] 0. 프로젝트 개요 (0) | 2022.07.21 |