


타겟 데이터
본 프로젝트는 교보문고의 분야별 베스트셀러에 대한 분석과 추천시스템 구현을 목적으로 한다. 따라서 프로젝트에 필요한 타겟 데이터는 다음과 같다.
- 교보문고 분야별 베스트 셀러의 정보 (목록, 출판사 등)
- 해당 도서의 키워드 (일본소설, 치유, 사회문제, 대화)
- 해당 도서 평점과 평점에 참여한 유저의 정보
- 해당 도서의 리뷰 (추후의 NLP 적용를 위한 플러스 알파)
교보문고는 분야별 베스트셀러 목록을 excel 파일로 제공한다. 따라서 베스트셀러의 데이터를 일일이 크롤링 해야하는 수고를 덜어 작업이 훨씬 순조로웠다.


베스트셀러 도서의 키워드 역시 제공한다. 키워드픽이라는 항목으로 도서의 분류, 혹은 내용에 대한 키워드를 선정하여 고객들이 구매 전 미리 알아볼 수 있도록 했다. 미리 실물 책을 읽어 보고 구매할 수 없는 온라인 서점의 특성을 고려했을 때 고객 입장에서 매우 유용한 서비스라고 생각한다. 동시에 교보문고에서는 키워드픽을 추천시스템에 그대로 활용하고 있으므로 추후에 본 프로젝트에서도 키워드픽을 기반으로 CBF 알고리즘을 적용할 예정이다.

Klover 서비스로 독자들의 리뷰와 평점을 제공하고 있다. 데이터 보호의 측면에서 유저 정보는 마스킹 처리 되었있으므로 그대로 게시한다. 만약 동일한 아이디로 여러 도서를 구매하고 평점을 매겼다면 CF 알고리즘의 적용이 가능할 것이다.
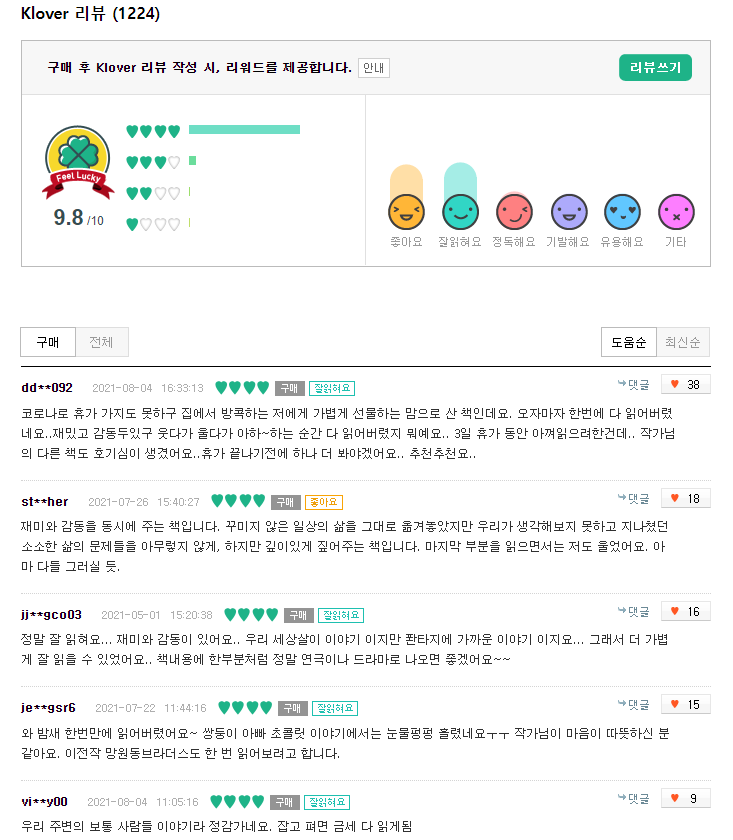
데이터 수집 : 크롤링 코드 작성
크롤링 실력은 여러가지 웹 사이트를 목표로 다양하게 접근하면서 자연스럽게 늘게 되지만 그럼에도 시행착오법 (a.k.a 노가다)의 과정이다. 프로젝트를 위한 크롤링 코드를 작성할 때 유의해야 할 점은 코드 개발의 목적이 어디에 있는가 하는 점이다. 간결하고도 멋진 코드를 작성해서 실행만 시키고 모든 항목을 자동으로 크롤링할 수 있으면 좋겠지만 실제로는 쉽지 않다. 때때로 알 수 없는 오류가 발생하기도 하며 웹 페이지에 따라 크롤링 할 수 없거나 javascript의 영향으로 모든 항목을 자동화하기 힘든 경우도 많다.
궁극적으로 크롤링을 하는 목적은 데이터를 수집하여 프로젝트의 재료를 마련하는 것이므로 코드 개발 자체에 너무 몰두할 필요는 없는것 같다. 말 그대로 수집만 하면 그만인 셈이다. (불법적인 요소를 포함하거나 데이터 저작권을 저해하지 않는다면.)
교보문고 웹 사이트의 경우에도 javascript의 영향으로 selector를 특정할 수 없는 이슈가 있었으며 리뷰 크롤링 시 마지막 페이지의 인덱스를 따는 과정이 힘들었다. 자동으로 다음 페이지로 넘겨 크롤링하기 위해서 아주 원시적인 알고리즘 코드를 작성하여 해결하였다. (오랜만에 종이와 펜으로 알고리즘을 만들었다...... )
크롤링 코드의 경우 조금만 시간이 지나도 적용되지 않는 경우가 많으므로 일종의 모티프만을 남기는 목적으로 게시한다.
### 라이브러리 ###
import requests
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import chromedriver_autoinstaller
import time
from tqdm import tqdm_notebook### 크롤링 전처리 ###
def preprocessing(total): # 리뷰 수
k_total = int(re.sub('\D','',total))
return k_total
def keyword_pre(keywords): # 도서 키워드
for keyword in keywords:
keyword_list.append(keyword.text)
def id_pre(ids): # 유저 id
for id in ids:
id_list.append(id.text)
def klovers_pre(klovers): # 유저의 평점
for klover in klovers:
klover_list.append(klover.text)
def comments_pre(comments): # 유저 리뷰
for comment in comments:
comment_list.append(comment.text)각각의 크롤링 항목에 대해 전처리 함수를 미리 만들어 놓고 바로 데이터프레임화 할 수 있도록 하였다. 필자의 경우 데이터 분석 목적으로 파이썬에 첫발을 내딛은 상태라 코드의 조악함과 비효율성에 대해서는 아주 많은 보완이 필요하다.
### 전체 리뷰 데이터 수집 ###
for j in tqdm_notebook(range(41, 120)): # 팀원에 따라 range 항목 조정
url = df.iloc[j][1]
title = df['도서명'][j]
# 크롬 웹 브라우저 실행 (keyword 검색결과)
chrome_path = chromedriver_autoinstaller.install()
driver = webdriver.Chrome(chrome_path)
driver.get('http://www.kyobobook.co.kr/product/detailViewKor.laf?mallGb=KOR&ejkGb=KOR&linkClass=01&barcode={}'.format(url)) # query : 바코드 숫자
time.sleep(1)
# 회원리뷰 클릭 : 그래야 klova 회원리뷰 목록이 나옴
try:
driver.find_element_by_partial_link_text('회원리뷰').click()
time.sleep(2)
keyword_list = []
id_list = []
klover_list = []
comment_list = []
total = driver.find_element_by_id('kloverTotal').text
k_total = preprocessing(total)
### 페이지 인덱스 구하는 알고리즘 ###
page_n = math.ceil(k_total / 5)
n =page_n -page_n % 10
m= page_n %10+3
# 키워드 수집
keywords = driver.find_elements_by_class_name('book_keyword > a')
keyword_pre(keywords)
# 스코어 수집
score = driver.find_element_by_class_name('score').text
i = 0
# 다음 페이지 클릭하기 위한 함수
while i < page_n :
# 유저아이디 수집
ids = driver.find_elements_by_css_selector('.box_detail_review .board_list .comment_wrap .id')
id_pre(ids)
# 클로버(평점)수집
klovers = driver.find_elements_by_css_selector('.comment_wrap .kloverRating > span')
klovers_pre(klovers)
# 유저리뷰 수집
comments = driver.find_elements_by_css_selector('.box_detail_review .board_list .comment_wrap .comment')
comments_pre(comments)
# 다음페이지 클릭
i +=1
time.sleep(1)
if i> n or k_total <= 50:
index = m
else:
index = 13
if i < page_n:
css_selector= '.box_detail_review > div.list_paging.align_center > div > a:nth-child({})'.format(index)
driver.find_element_by_css_selector(css_selector).click()
else:
print(j,'th done:',title)
driver.close()
time.sleep(2)
data = [(id_list,klover_list,comment_list)]
lable = ['id','klover','comment']
df_temp= pd.DataFrame(zip(id_list,klover_list,comment_list),columns=lable)
# 키워드, 스코어, 리뷰 수 컬럼 추가
keyword_col = ' '.join(keyword_list)
df_temp['keyword'] = keyword_col
df_temp['score']= score
df_temp['total'] = k_total
df_temp['title'] = title
# 도서명으로 신규파일 저장
df_temp.to_excel('{}.xlsx'.format(title))
except:
driver.close()
print(j,'th error:',title) # 에러 발생할 경우 해당 서적 출력
df_keyword = df_keyword.append([df_temp.iloc[0]])
df_keyword.to_excel모든 도서가 타겟 데이터의 항목을 빠짐없이 가지고 있는 것은 아니다. 키워드가 없거나 독자들의 리뷰가 없는 도서도 존재하였고 그럼에도 오류가 발생하지 않고 자동으로 다음 항목으로 넘어갈 수 있도록 했다. 타겟 데이터는 도서 약 3000여권, 리뷰는 18만건 이상이므로 사소한 데이터의 유실보다 빠른 시간안에 팀원이 나눠서 크롤링할 수 있는 것이 더 중요했기 떄문이다. 컴퓨팅 파워와 상관없이 모든 팀원이 밤새 코드를 실행시키고 다음 날 아침에 완료될 정도였다.
time.sleep을 길게, 자주 걸어 크롤링이 매우 오래 걸렸지만 그래도 켜놓고 자면 오류없이 수집될 수 있도록 만들었다. 부트캠프 초창기라 저 코드 작성하는데 거의 밤을 지세운 추억이 새록새록 떠오른다. 아마 지금은 실행이 안될 것을 생각하니 왠지 서글프다.
수집 결과

크롤링 결과 3,240권에 대한 182,115건의 독자 리뷰 데이터를 구축하였다. 이제 간단히 전처리해서 베스트셀러 데이터를 분석하고 시각화 해보자.
※ 프로젝트를 진행하면서 알게되었는데 '경제' 분야을 빠뜨렸다....... 아마 팀원끼리 카테고리를 나눠 크롤링하는 과정에서 실수로 생략된 것 같다..... 매우 아쉬운 점이다.
해당 데이터는 데이터 분석 공부 목적으로 수집하였으며 프로젝트 완료 후 폐기하였습니다. 또한 유저 데이터의 마스킹 처리로 개인 정보 식별을 방지하였음을 알립니다.
'Jay's Project > 교보문고 책 추천시스템 구현' 카테고리의 다른 글
| [교보문고 베스트셀러 분석 / 추천시스템] 4. 추천시스템 (CBF) (0) | 2022.07.25 |
|---|---|
| [교보문고 베스트셀러 분석 / 추천시스템] 3. 베스트셀러 분석 (0) | 2022.07.23 |
| [교보문고 베스트셀러 분석 / 추천시스템] 1. 프로젝트 기획 (0) | 2022.07.21 |
| [교보문고 베스트셀러 분석 / 추천시스템] 0. 프로젝트 개요 (0) | 2022.07.21 |