

pandas dataframe 행 추가
1. append()
2. loc()
pandas 라이브러리에서 dataframe 자료형에 행을 추가하는 방법을 정리한다.
예제의 자료는 전 국민의 데이터인 kaggle 타이타닉 데이터셋의 train에서 몇 가지 컬럼만 가져와 사용하였다.
import pandas as pd
df = pd.read_csv('./dataset/data_titanic/train.csv')
df = df[['PassengerId', 'Survived','Name','Sex']]
df
1. append()
appned() 메서드는 데이터프레임에 행을 추가하는 대표적인 방법이다.
새롭게 추하가는 자료의 형태는 시리즈나 딕셔너리, 데이터프레임 모두 사용 가능하다.
우선은 딕셔너리 형태의 새로운 행을 추가해 보자.
# 1. append() : dictionary or series
new_row = {'Survived':'1', 'Name':'Jay,Oh', 'Sex':'male'}
df.append(new_row)
새로 추가되는 행이 index 값이 설정되어 있지 않으므로 ingore_index=True 옵션을 통해 추가되는 행의 인덱스를 무시해서 넣어야 한다.
df2 = df.append(new_row, ignore_index=True)
df2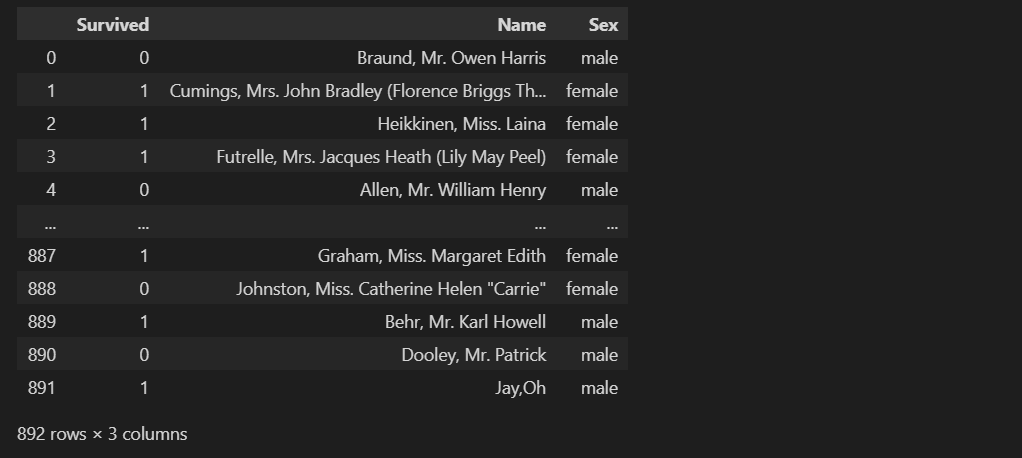
다음으로 추가할 행을 데이터프레임 자료형으로 변환한 뒤 append 메서드를 사용한다.
# 2. append() : dataframe
new_row = [(1, 'Jay,Oh','male')]
new_row = pd.DataFrame(new_row, columns=df.columns
new_row
df3 = df.append(new_row)
df3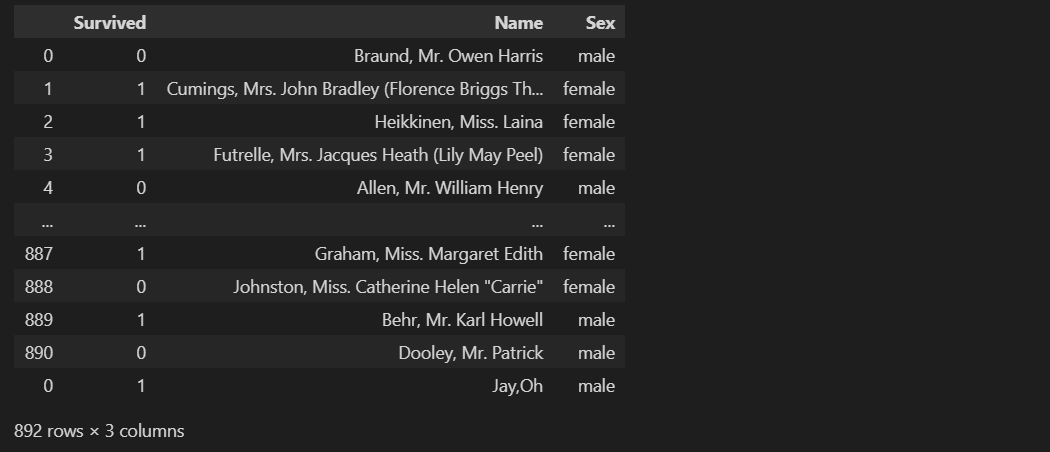
데이터프레임 자료형의 경우 서로의 인덱스가 상충하므로 ignore_index 옵션을 설정하지 않으면 위와 같이 원본의 인덱스를 모두 살린 후 합쳐진다. igore_index=True의 경우 행을 추가하려는 기존 데이터프레임의 인덱스를 따르게 된다.
df3 = df.append(new_row, ignore_index=True)
df3
2. loc : 인덱스명 이용하기
원본 데이터 프레임을 바꾸면 실습하기 힘들어서 따로 카피해놓고 시작한다.
df4 = df.copy()
df5 = df.copy()loc는 label 값으로 인덱싱을 하는 방법인데 지금 예제의 자료는 행의 인덱싱 숫자가 그대로 사용되었다.
제일 마지막에 새로운 행을 추가하기 위해서 기존의 데이터프레임의 마지막 행의 인덱스를 가져와 본다.
df.iloc[-1:]
기존 데이터 프레임의 마지막 인덱스가 890이므로 891을 인덱스 명으로 행을 추가한다. (아니어도 상관은 없음)
# loc[] : index명 이용
df4.loc['891'] = [1, 'Jay,Oh','male']
df4
iloc[]
수정은 가능 but 추가는 불가
# iloc[] : location 이용 -> 추가는 불가능
df5.iloc[891] = [1, 'Jay,Oh','male']
df5
합치려는 기존 데이터프레임의 범위를 초과할 수 없는 오류 발생!
concat()
concat() 으로도 가능하지만 이는 기본적으로 dataframe을 합치는 메서드 이므로 따로 다루기로 한다.
# iloc[] : location 이용 -> 추가는 불가능
df5.iloc[891] = [1, 'Jay,Oh','male']
df5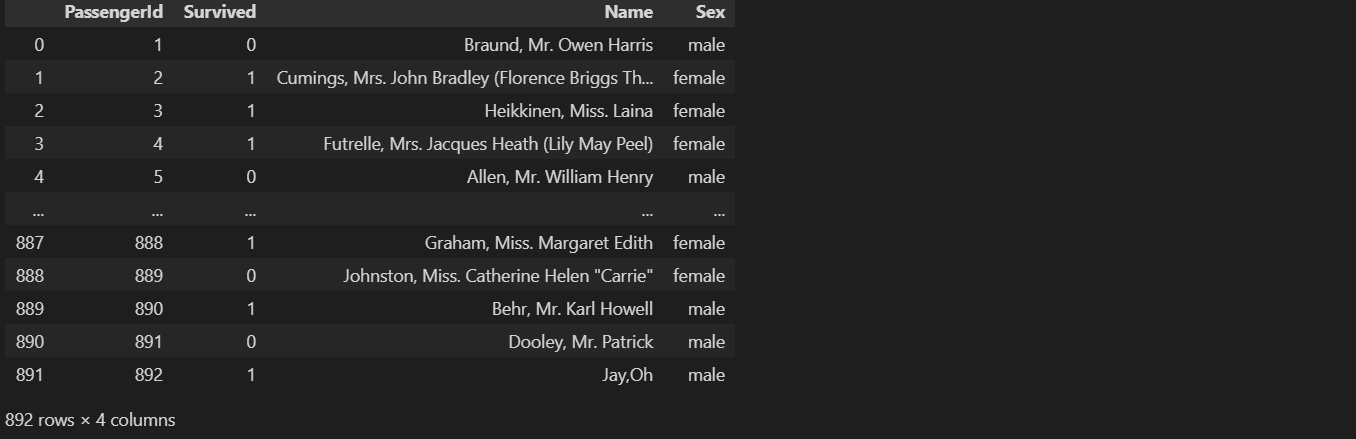
pandas dataframe 행 제거
drop()
DataFrame.drop(labels=None, axis=0, index=None, columns=None, level=None, inplace=False, errors='raise')
dataframe에서 행, 열 제거 모두 사용되는 대표적인 방법이다.
axis=0 이 행이고 default 값이며, 열 삭제를 위해서는 aixs=1로 입력한다.
drop 메서드는 본래의 데이터가 바뀌지 않으므로 inplace=True 옵션이나 객체로 다시 지정해야 한다.
* inplace=True, False(defalult)
- True : 기존 데이터프레임 자체가 변경
- False : 기존 데이터프레임 copy후 적용한 결과 반환 → 기존 데이터 프레임은 변경 안됨
df.drop(0,inplace=True)
# same
# df = df.drop(0)
df
첫번째 행 index을 넣어 drop(0, inplace=True)로 제거한 모습이다.
'Data Science > python' 카테고리의 다른 글
| [python] selenium element 클릭 (0) | 2022.03.14 |
|---|---|
| [pandas] pandas_profiling 정리 (0) | 2022.02.02 |
| sklearn.model_selection.GridSearchCV 정리 (0) | 2022.01.30 |
| sklearn.model_selection.cross_val_score 인자 정리 (0) | 2022.01.30 |
| [pandas] dataframe/series 형태 train_test_split() 적용 (0) | 2022.01.30 |