

meta 태그에서 인코딩 방식 추출하기
html meta태그 안에 인코딩 방식이 지정되어 있다. 각 페이지 별로 인코딩 방식이 다를 수 있기 떄문에 해당 url을 통해 html 자료를 스크래이핑 한후 meta 태그 부분을 선별해내어 인코딩 방식이 무엇인지 알아낸다. urllib.request 패키지를 통해 스크레이핑할 url을 가져오고 bytes 자료형으로 변환하여 읽어준다. 실습은 한빛출판사 웹 페이지를 대상으로 한다.
import sys
from urllib.request import urlopen
# urlopen() 함수는 HTTPResponse 자료형의 객체를 반환합니다.
f = urlopen('http://www.hanbit.co.kr/store/books/full_book_list.html')
# bytes 자료형의 응답 본문을 일단 변수에 저장합니다.
bytes_content = f.read()
bytes_content
charset은 html 앞 부분에 작성되어 있는 경우가 많으므로 bytes 형식으로 읽어온 앞부분 1024바이트를 ASCII 문자로 디코딩한다. 1024바이트 이후의 문자는 replace character로 변환되어 에러를 처리한다.
# charset은 HTML의 앞부분에 적혀 있는 경우가 많으므로 응답 본문의 앞부분 1024바이트를 ASCII 문자로 디코딩해 둡니다.
# ASCII 범위 이위의 문자는 U+FFFD(REPLACEMENT CHARACTER)로 변환되어 예외가 발생하지 않습니다.
scanned_text = bytes_content[:1024].decode('ascii', errors='replace')
scanned_text
표시된 부분에 <meta charset='utf-8'>로 표시되어 있음을 볼 수 있다. 해당 웹 페이지의 인코딩 방식은 utf8 이다.
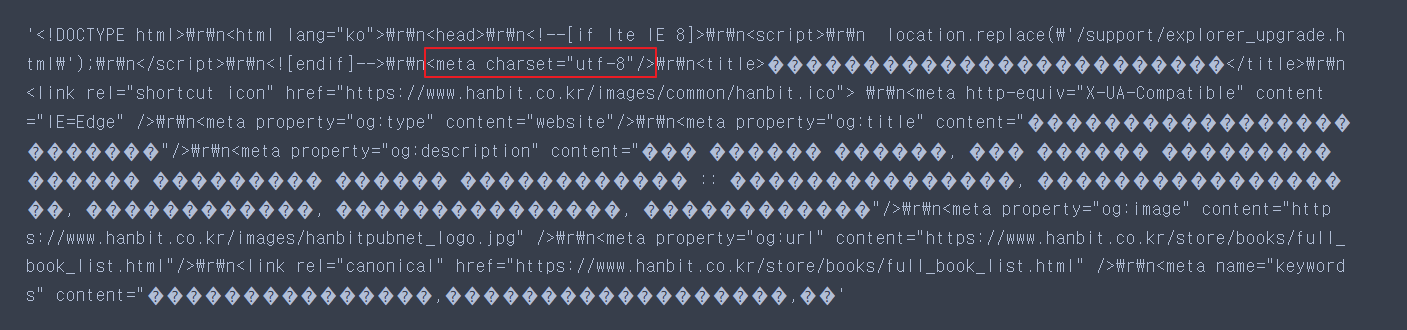
직접적으로 charset 값을 추출하기 위해 정규표현식을 이용한다. re.search('regex(정규표현식)', 찾을 범위)를 쓴다.
- ["\']? : [홑따옴표 or 쌍따옴표] 가 0번 또는 1번 반복, \는 escape로 특수문자 의미 그대로 쓴다는 표시
- ([\w-]+) : [alphanumeric(알파벳,숫자)와 '_' or - 한번 이상 반복 $ ()로 그룹화
# 디코딩한 문자열에서 정규 표현식으로 charset 값을 추출합니다.
match = re.search('charset=["\']?([\w-]+)', scanned_text)
match
# ["\']? : 홑따옴표나 쌍따옴표 0 또는 1번 반복
# ([\w-]+) : 알파벳,숫자,언더바(_),대쉬(-) 한 번 이상 반복 그룹
이후 추출된 utf9 인코딩 방식으로 bytes 형식의 자료 전체를 디코딩 한 후 저장한다.
# match(charset)가 존재하는 경우
if match:
encoding = match.group(1)
else:
# charset이 명시돼 있지 않으면 UTF-8을 사용합니다.
encoding = 'utf-8'
# 추출한 인코딩을 표준 오류에 출력합니다.
print('encoding:', encoding, file=sys.stderr)
# 추출한 인코딩으로 다시 디코딩합니다.
text_html = bytes_content.decode(encoding)
# 응답 본문을 표준 출력에 출력합니다.
print(text_html)
'Data Science > python' 카테고리의 다른 글
| 머신러닝 개요 (0) | 2022.01.15 |
|---|---|
| [Regression] 머신러닝 회귀분석 개요 (0) | 2022.01.13 |
| [python] 정규표현식 .*? 해석 (0) | 2022.01.05 |
| [python] 정규 표현식 정리 (0) | 2022.01.03 |
| [python] selenium 크롤링에서 class/id/name이 없는 링크 태그 접근하기 (0) | 2022.01.03 |