

지난 번 네이버 블로그 크롤링과 유사하게 네이버에서 키워드 검색 후 관련 뉴스 기사 크롤링을 실습해 본다. 마찬가지로 처음에는 자동검색을 통해 url들을 수집한 뒤 pandas로 데이터프레임화 한 후 csv로 저장한다. 그 다음 csv를 로드한 뒤 url을 하나씩 열어 기사 본문과 댓글, 좋아요 등의 감정 수집까지 진행한다. 역시나 처음에는 전체 구조를 for문으로 만들기 전에 하나의 기사로 코드를 실험한다.
0. 라이브러리 & 모듈
- Selenium ActionChains : 여러 개의 동작을 체인으로 묶어서 저장하고 실행한다.
- re : 정규표현식을 사용할 수 있는 모듈
# 라이브러리 import
import pandas as pd
import numpy as np
from selenium import webdriver
from selenium.webdriver import ActionChains as AC # 여러 동작을 체인으로 묶어 실행
import chromedriver_autoinstaller
from tqdm import tqdm
from tqdm.notebook import tqdm
import re # 정규표현식
from time import sleep
import time
# 워닝 무시
import warnings
warnings.filterwarnings('ignore')# 데이터 수집할 키워드 지정
keyword = "카카오"1. 네이버 뉴스들 url 수집
- 크롬창 띄우기
- driver.get(url) : 네이버 메인화면에서 검색 창에 키워드를 입력 후 뉴스 탭을 클릭한 url 자체를 넣어준다.
# 크롬창 띄우기
chrome_path = chromedriver_autoinstaller.install()
driver = webdriver.Chrome(chrome_path)
driver.get("https://search.naver.com/search.naver?where=news&sm=tab_jum&query={}".format(keyword))
time.sleep(2)
- page1에서 네이버뉴스 url 수집하기
- 각 언론사가 아닌 네이버 뉴스에서 게시된 기사만을 대상으로 하기 때문에 네이버뉴스 text의 링크만 가져온다.
# page1에서 네이버뉴스 text를 가진 url 수집하기
things = driver.find_elements_by_link_text('네이버뉴스') #elements : 여러가지를 리스트로 가져옴
- 수집한 네이버 뉴스 url중 href로 기사링크 가져오기
- get_attribute('href')로 대상 url의 기사 링크만 가져와서 url_list 의 빈 리스트에 넣는다
# 수집한 네이버 뉴스 url 중 링크 가져오기
url_list = []
for thing in things:
url = thing.get_attribute('href')
url_list.append(url)
print(len(url_list))
url_list- pandas 데이터프레임 변환 및 csv 파일로 저장
- df=pd.DataFrame({'url':url_list}) : url_list라는 리스트를 column명을 url로 저장
df = pd.DataFrame({"url":url_list})
df.to_csv('navernews_urls.csv')2. 기사 크롤링 (한 개로 test)
- 저장해둔 url 불러오기
df = pd.read_csv('navernews_urls.csv')
df['url']
len(df['url'])# 전체 data를 담을 딕셔너리 생성
dict = {}
# 뉴스 크롬창 띄우기
chrome_path = chromedriver_autoinstaller.install()
driver = webdriver.Chrome(chrome_path)
driver.get(df['url'][0])- 기사 제목, 날짜, 추천수 수집
# 기사 제목
title = driver.find_element_by_css_selector('.tts_head')
title = title.text
print(title)
# 기사 날짜
date = driver.find_element_by_css_selector('.t11')
date = date.text
print(date)
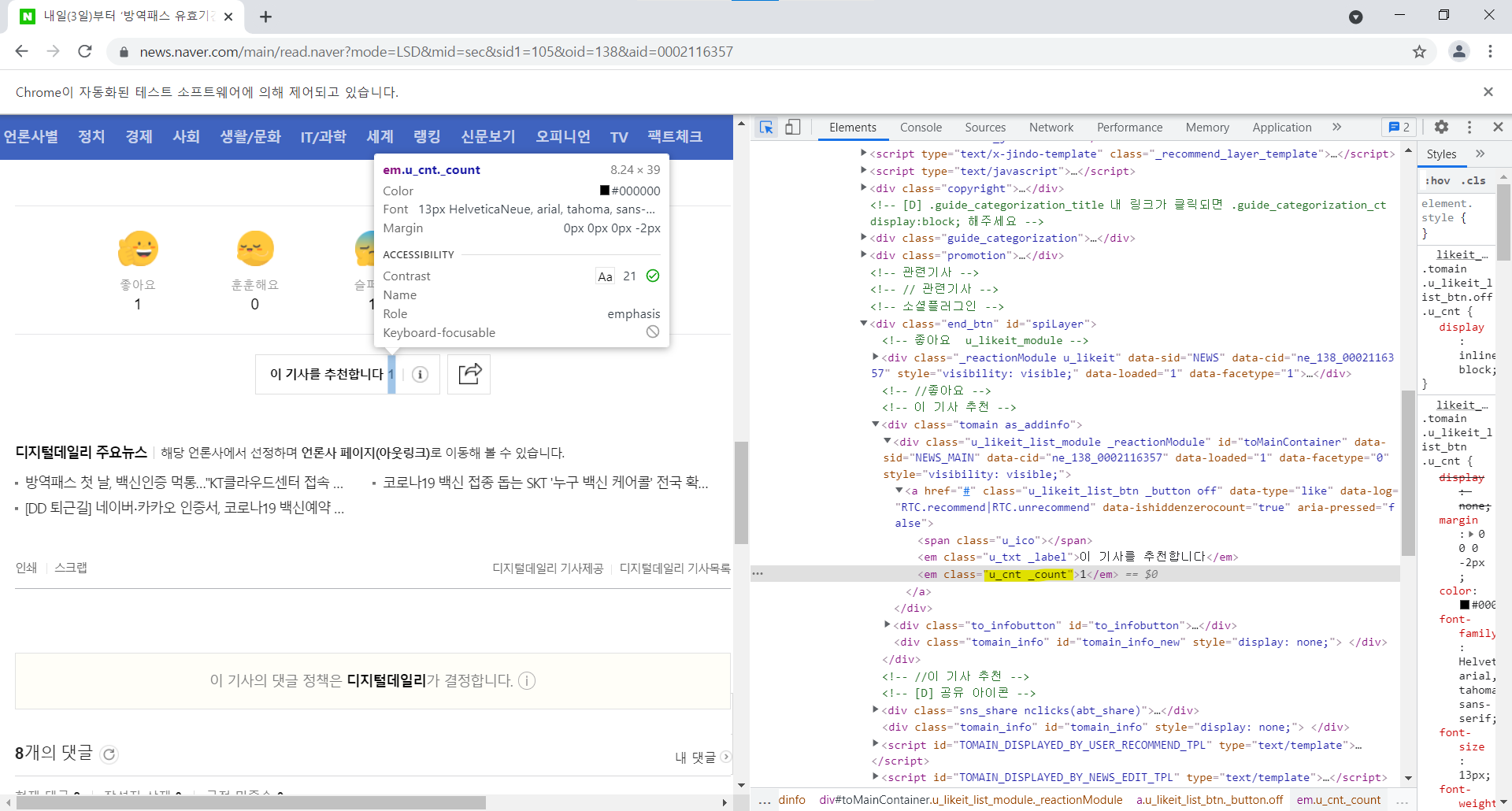
# 기사 추천수 날짜
up = driver.find_element_by_css_selector('.tomain.as_addinfo .u_cnt._count')
up = up.text
print('기사 추천 수: ', up)

- 기사 감정 수집 (좋아요, 훈훈해요, 슬퍼요, 화나요)
selenium 크롤링에서 가장 애를 먹는 부분이다. 분명 좋아요 수를 직접 가르키는 class를 찾았음데도 에러가 발생할 때가 있다. 부모 클래스 까지 같이 작성을 해줘야 하는데 도대체 어디 부분까지 올라가야 하는지, 코드로 작성을 해야 하는지 어려움을 겪는다. 밑에서는 상위 클래스에 'end_btn' 클래스가 있고 제일 하위에 각각 'u_likeit_list.good/warm/sad/angry/want'로 나뉘어 있다
따라서 전체 구조를 파악한 뒤 상위 클래스 까지는 어느정도 경험적으로 찾을 수밖에 없는 것이 현재의 실력이다.
# 좋아요
like = driver.find_element_by_css_selector(".end_btn .u_likeit_list.good .u_likeit_list_count._count")
like = like.text
print(like)
# 훈훈해요
warm = driver.find_element_by_css_selector(".end_btn .u_likeit_list.warm .u_likeit_list_count._count")
warm = warm.text
print(warm)
# 슬퍼요
sad = driver.find_element_by_css_selector(".end_btn .u_likeit_list.sad .u_likeit_list_count._count")
sad = sad.text
print(sad)
# 화나요
angry = driver.find_element_by_css_selector(".end_btn .u_likeit_list.angry .u_likeit_list_count._count")
angry = angry.text
print(angry)
# 후속기사 원해요
want = driver.find_element_by_css_selector(".end_btn .u_likeit_list.want .u_likeit_list_count._count")
want = want.text
print(want)

3. 댓글 수집
- 기사 댓글 갯수 : 댓글 개수를 가져온 뒤 정수형으로 변환한다
review_count = driver.find_element_by_css_selector(".u_cbox_info_txt").text
review_count = int(review_count)- 더보기 클릭 횟수
- 네이버 기사 댓글의 첫 레이아웃은 20개까지 댓글이 표시되므로 20개 이상은 댓글 더보기를 클릭하기 위해 20으로 나눈 몫을 미리 변수로 저장해 놓는다
moreview_num = review_count//20
moreview_num- 댓글 버튼 클릭
# 댓글 버튼 클릭
driver.find_element_by_css_selector(".u_cbox_btn_view_comment").click()
time.sleep(1)- 더보기 버튼 여러번 클릭하기
- 댓글 전체를 크롤링 하기 위해 while문을 통해 댓글 더보기 버튼을 여러번 클릭한다. 이 때 위에서 저장해놓은 변수 moreview_num 을 활용한다.
# 더보기 버튼 여러번 클릭하기
k=0
while k <= moreview_num: # 더보기 횟수만큼 반복
try:
driver.find_element_by_css_selector(".u_cbox_page_more").click() # 더보기 버튼 클릭
time.sleep(1)
k = k+1
except:
break # 에러나면 클릭 반복문을 빠져나가라- 댓글 수집하기
# review 수집하기
review_list = []
overlays1 = ".u_cbox_contents"
reviews = driver.find_elements_by_css_selector(overlays1)
for review in tqdm(reviews):
review = review.text
review_list.append(review)
print(len(review_list))
review_list
- 개별 기사들은 target_info 딕셔너리에 각각을 분류하여 key&value로 넣기
target_info = {}
target_info['기사명'] = title
target_info['날짜'] = date
target_info['기사 추천 수'] = up
target_info['댓글'] = review_list
target_info['좋아요'] = like
target_info['훈훈해요'] = warm
target_info['슬퍼요'] = sad
target_info['화나요'] = angry
target_info['후속기사 원해요'] = want
target_info
'Data Science > python' 카테고리의 다른 글
| [python] 정규 표현식 정리 (0) | 2022.01.03 |
|---|---|
| [python] selenium 크롤링에서 class/id/name이 없는 링크 태그 접근하기 (0) | 2022.01.03 |
| [python] selenium 웹크롤러 정리 (0) | 2022.01.02 |
| [python] selenium 네이버 블로그 크롤링(2) (0) | 2022.01.02 |
| [python] selenium 네이버 블로그 크롤링(1) (0) | 2022.01.01 |