

지난 포스팅에서는 selenium을 이용해 네이버 검색어를 자동으로 입력해서 블로그 제목과 url을 크롤링 해봤다.
이번에는 지난 포스팅에서 저장한 excel 파일을 불러와서 블로그 내용까지 크롤링하는 연습이다.
모듈&라이브러리
import sys
import os
import pandas as pd
import numpy as np파일 로드 후 확인
# "url_list.xlsx" 불러오기
url_load = pd.read_excel("blog_url.xlsx")
url_load = url_load.drop("Unnamed: 0", axis=1) # 불필요한 칼럼 삭제
num_list = len(url_load)
print(num_list)
url_load
2. 크롬 드라이버 실행 및 url 입력
- i=0 부터 크롤링 되는 지 시도해봄
- driver.get('url')로 저장되있는 url의 블로그를 연다
chrome_path = chromedriver_autoinstaller.install()
driver = webdriver.Chrome(chrome_path)
i = 0
url = url_load['url'][i]
driver.get(url) # 글 띄우기
time.sleep(1)iframe 접근
- 창에 정보가 있어도 접근이 되지 않는다면 irame으로 구성되어 있는 지 살펴본다.
- 주로 네이버 블로그, 카페 등에서 사용되며 이는 프레임 이름을 확인해서 전환하는 코드가 필요하다.
→ driver.switch_to.frame('프레임이름')
https://m.blog.naver.com/PostView.naver?isHttpsRedirect=true&blogId=kiddwannabe&logNo=221253004219
크롤링 중 Frame 전환하기(iFrame 크롤링 하기)
Edited 2020.02.07 switch_to_frame() 명령어가 switch_to.frame() 으로 변경되었습니다. Added 2021.01....
blog.naver.com
# irame 이름 확인 및 출력
iframes = driver.find_elements_by_css_selector('iframe')
for iframe in iframes:
print(iframe.get_attribute('name'))
mainFrame
# iframe 접근
driver.switch_to.frame('mainFrame')
time.sleep(1)
크롤링 시작
- 전체 데이터를 담을 딕셔너리와 개별 블로그 내용을 담을 딕셔너리 두개를 생성한다 → 데이터 프레임 구성을 위함
# 제목 크롤링 시작
overlays = ".se-module.se-module-text.se-title-text"
tit = driver.find_element_by_css_selector(overlays) # title
title = tit.text # 셀레늄 덩어리 안의 텍스트 가져오기
title
# 글쓴이 크롤링 시작
overlays = ".link.pcol2"
nick = driver.find_element_by_css_selector(overlays) # nickname
nickname = nick.text
nickname
# 날짜 크롤링
overlays = ".se_publishDate.pcol2"
date = driver.find_element_by_css_selector(overlays) # datetime
datetime = date.text
date
# 내용 크롤링
overlays = ".se-component.se-text.se-l-default"
contents = driver.find_elements_by_css_selector(overlays) # contents
contents
contents[0].text- 제목 클래스

- 글쓴이 클래스
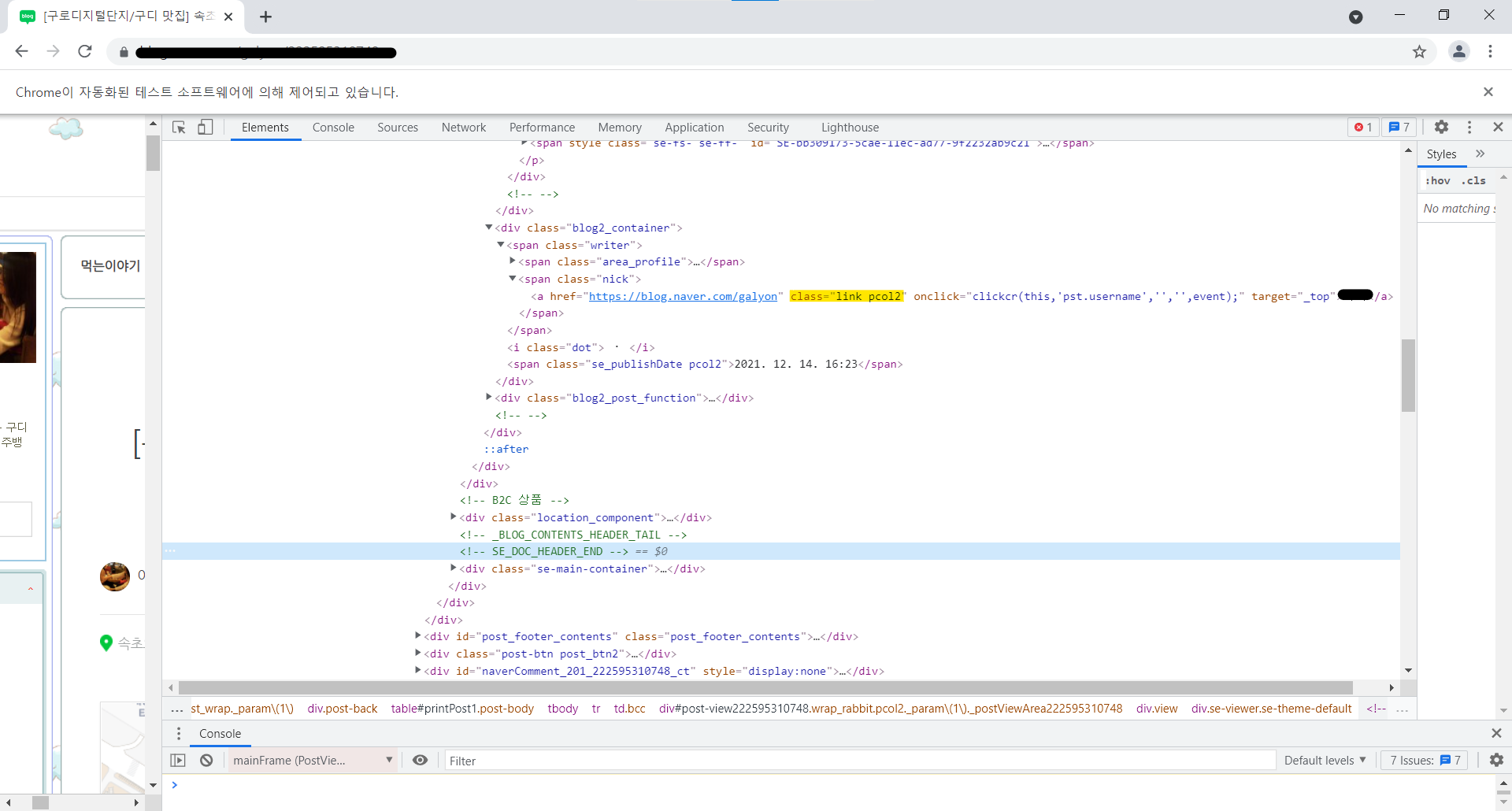
- 본문 크롤링 (처음에는 시행착오법으로....)

크롤링한 본문을 .join() 로 하나의 글로 합치기
content_list = []
for content in contents:
content_list.append(content.text)
content_str = ' '.join(content_list) # content_str
content_str
# 글 하나는 target_info라는 딕셔너리에 담기게 되고, 전체 url 수의 글들은 dict라는 딕셔너리에 담긴다
target_info['title'] = title
target_info['nickname'] = nickname
target_info['datetime'] = datetime
target_info['content'] = content_str
dict[0] = target_info판다스로 만들고 저장하기
- DataFrame.from_dict() : 딕셔너리를 데이터프레임으로 반환
#v판다스로 만들기
import pandas as pd
result_df = pd.DataFrame.from_dict(dict, orient='index') # 딕셔너리를 데이터프레임으로
result_df
# 엑셀로 저장하기
result_df.to_excel("blog_content.xlsx", encoding='utf-8-sig')
※ for문으로 만든 전체 코드
dict = {} # 전체 크롤링 데이터를 담을 그릇
# 수집할 글 갯수 정하기
number = 20
# 수집한 url 돌면서 데이터 수집
for i in tqdm_notebook(range(0, number)):
# 글 띄우기
url = url_load['url'][i]
chrome_path = chromedriver_autoinstaller.install()
driver = webdriver.Chrome(chrome_path)
driver.get(url) # 글 띄우기
# 크롤링
# 예외 처리
try :
# iframe 접근
driver.switch_to.frame('mainFrame')
target_info = {} # 개별 블로그 내용을 담을 딕셔너리 생성
# 제목 크롤링
overlays = ".se-module.se-module-text.se-title-text"
tit = driver.find_element_by_css_selector(overlays) # title
title = tit.text
# 글쓴이 크롤링
overlays = ".nick"
nick = driver.find_element_by_css_selector(overlays) # nickname
nickname = nick.text
# 날짜 크롤링
overlays = ".se_publishDate.pcol2"
date = driver.find_element_by_css_selector(overlays) # datetime
datetime = date.text
# 내용 크롤링
overlays = ".se-component.se-text.se-l-default"
contents = driver.find_elements_by_css_selector(overlays) # contents
content_list = []
for content in contents:
content_list.append(content.text)
content_str = ' '.join(content_list) # content_str
# 글 하나는 target_info라는 딕셔너리에 담기게 되고,
target_info['title'] = title
target_info['nickname'] = nickname
target_info['datetime'] = datetime
target_info['content'] = content_str
# 각각의 글은 dict라는 딕셔너리에 담기게 됩니다.
dict[i] = target_info
time.sleep(1)
# 크롤링이 성공하면 글 제목을 출력하게 되고,
print(i, title)
# 글 하나 크롤링 후 크롬 창을 닫습니다.
driver.close()
# 에러나면 현재 크롬창을 닫고 다음 글(i+1)로 이동합니다.
except:
# print("에러",i, title)
driver.close()
time.sleep(1)
continue
# 중간,중간에 파일로 저장하기
if i == 30 or i==50 or i==80:
# 판다스로 만들기
import pandas as pd
result_df = pd.DataFrame.from_dict(dict, 'index')
# 저장하기
result_df.to_excel("blog_content.xlsx", encoding='utf-8-sig')
time.sleep(3)
print('수집한 글 갯수: ', len(dict))
print(dict)'Data Science > python' 카테고리의 다른 글
| [python] selenium 네이버 뉴스 기사 크롤링 (0) | 2022.01.02 |
|---|---|
| [python] selenium 웹크롤러 정리 (0) | 2022.01.02 |
| [python] selenium 네이버 블로그 크롤링(1) (0) | 2022.01.01 |
| [python] 딕셔너리(dictionary) (0) | 2021.12.25 |
| [python] 튜플(Tuple) (0) | 2021.12.25 |