


기술 스택 분석에 이어 한글 명사만 추출하여 데이터 분석가 채용 공고에 빈출한 키워드는 무엇인지 분석해 본다. 각각의 용어로서 고유명사로 쓰인 알파벳과 달리 한글은 명사를 직접 형태소 분석기를 통해 추출하고 결과를 탐색하여 불용어 사전까지 작성해야 한다. 분류(Classification)과 같은 머신러닝을 적용하지 않는 프로젝트이며 기술 스택이나 분석 방법과 같은 영어로 된 용어말고 어떤 키워드들이 빈출하는 지 알아보기 위한 과정이다. 따라서 형태소 분석기를 이용하며 명사만을 가져오는 것을 목적으로 한다.
0. 모듈 & 라이브러리
#### konlpy 설치 (jpype, java_home 환경변수 설정, 시스템파일 수정), wordcloud 설치 과정은 따로 기재하지 않았습니다. #####
import os
import sys
import pandas as pd
import numpy as np
import re
from konlpy.tag import Okt # 형태소분석기 : Openkoreatext
from collections import Counter # 빈도 수 세기
from wordcloud import WordCloud # wordcloud 만들기
import matplotlib.pyplot as plt # 시각화
import matplotlib as mpl
import seaborn as sns
from matplotlib import font_manager, rc # font 설정
import nltk # natural language toolkit : 자연어 처리
# matplotlib 그래프 한글폰트 깨질 때 대처(Mac & Window)
import platform
if platform.system() == 'Windows':
# 윈도우인 경우
font_name = font_manager.FontProperties(fname="c:/Windows/Fonts/malgun.ttf").get_name() # 한글 폰트 깨지는 겨우
rc('font', family=font_name)
else:
# Mac 인 경우
rc('font', family='AppleGothic')
1. 데이터 전처리
# 형태소 분석기를 통해 명사만 추출하는 함수
def tokenizer_konlpy(text):
okt=Okt()
return [word for word in okt.nouns(text) if len(word)>1] # 한 글자 명사는 제외
noun = tokenizer_konlpy(text)
print(noun)
한국어처리 패키지인 KoNLPy 패키지를 활용하여 전처리를 진행하였다. KonNLPy는 Hannanum, Kkma, Mecab, Komoran, Okt(구 Twitter) 등의 형태소 분석기를 지원한다. 이 중 Okt(Open korean text) 형태소 분석기를 이용하여 명사만 가져왔다. 형태소 분석기 별로 성능비교는 해보지 않았지만 명사만 추출하는 간단한 작업이므로 자주 쓰던 Okt로 명사 태그만 가져왔다. 또한 한글자 명사는 분석에 용이하지 않고 불용어 처리 단계에서 번거로울 것 같아 두글자 이상의 단어만 추출하였다.
# 추출한 명사의 빈도 수 세기
kor_counted = Counter(noun)
# 빈도수 상위 100개를 내림차순으로 표시
kor_counted_ranked = kor_counted.most_common(100)
kor_counted_ranked
전과 동일하게 Counter를 이용해 빈도를 세고 상위 100개의 단어만 kor_counted_ranked 로 저장하였다. 먼저 전체 빈도 수를 파악한 뒤 상위에 있는 명사 중 불용어 리스트에 넣을 항목을 정한다. 예를 들면 '대한', '관련', '기반' 등의 명사들은 맥락상 그 다음에 나올 기술 스택이나 요구 스킬들을 수식하므로 제외한다. 우선 상위 100개 중 불용어 사전을 정한 후 다시 빈도 수를 나타내어 살펴보는 과정을 반복한다. 번거롱누 작업이지만 몇 번만 반복하면 아래와 같이 보다 분석에 목적적합한 단어들을 발견할 수 있다.
stop_words = ['데이터','분석','대한','관련','기반','이상','통해','통한','프로','덕트','위해',] # 불용어 사전 만들기
# '데이터', '분석'은 검색 키워드라 제거한다. 많은 빈도수를 가지지만 분석의 의미가 없다.cleaned_kor = [word for word in noun if not word in stop_words] #불용어 제거
cleaned_kor
# 각각 전처리가 완료된 영어 토큰 리스트 word_tokens와 한글 토큰 리스트 cleaned_kor를 합쳐서 전체 리스트를 만든다.
cleaned_all = word_tokens + cleaned_kor
len(cleaned_all)
# 전체 리스트 빈도 수
counted_all = Counter(cleaned_all)
counted_all_ranked = dict(counted_all.most_common())
counted_all_ranked
저번 포스팅까지 전처리가 완료된 영어 토큰들의 리스트를 이번에 분석한 한글 명사 토큰 리스트와 합쳐서 전체 토큰들을 만들었다. 압도적으로 한글 명사의 빈도가 높지만 따로 스케일 조정은 하지 않고 그대로 분석하였다. 통합된 토큰들을 빈도수로 정렬하고 딕셔너리로 만들었다. 이제 준비는 끝났다.
2. 데이터 시각화
2.1 word cloud
#wordcloud 만들기
wc = WordCloud(font_path = 'C:\Windows\Fonts\malgun.ttf',background_color="white",width=1500, height=500).generate_from_frequencies(counted_all_ranked) # font 경로 개별적으로 설정해야함
plt.figure(figsize = (40,40))
plt.imshow(wc)
plt.axis('off')
plt.show()
2.2 Barplot
df_keyword = pd.DataFrame.from_dict(counted_all_ranked,orient='index')
df_keyword['keyword'] = df_keyword.index
df_keyword=df_keyword.rename(columns={0:'count'})
df_keyword = df_keyword[['keyword','count']]
df_keyword.reset_index(drop=True,inplace=True) # drop=True 기존 인덱스 삭제
df_keyword2 = df_keyword[df_keyword['count']>=30]
df_keyword2
딕셔너리 상태에서 dataframe으로 자료를 변환한 뒤 빈도가 30 이상인 단어를 대상으로 분석 범위를 결정하였다.
plt.figure(figsize=(20, 10))
bar=sns.barplot(data=df_keyword2,x='keyword', y='count')
bar.set_title('Preferred skills for Data Analyst', fontsize=18)
bar.set_xlabel('Skill', fontdict={'size':16}) # x축 이름
bar.set_ylabel('Count', fontdict={'size':16})
for p in bar.patches: # count 넣기
height = p.get_height()
bar.text(p.get_x() + p.get_width() / 2., height + 1, height, ha = 'center', size = 15,)
plt.show()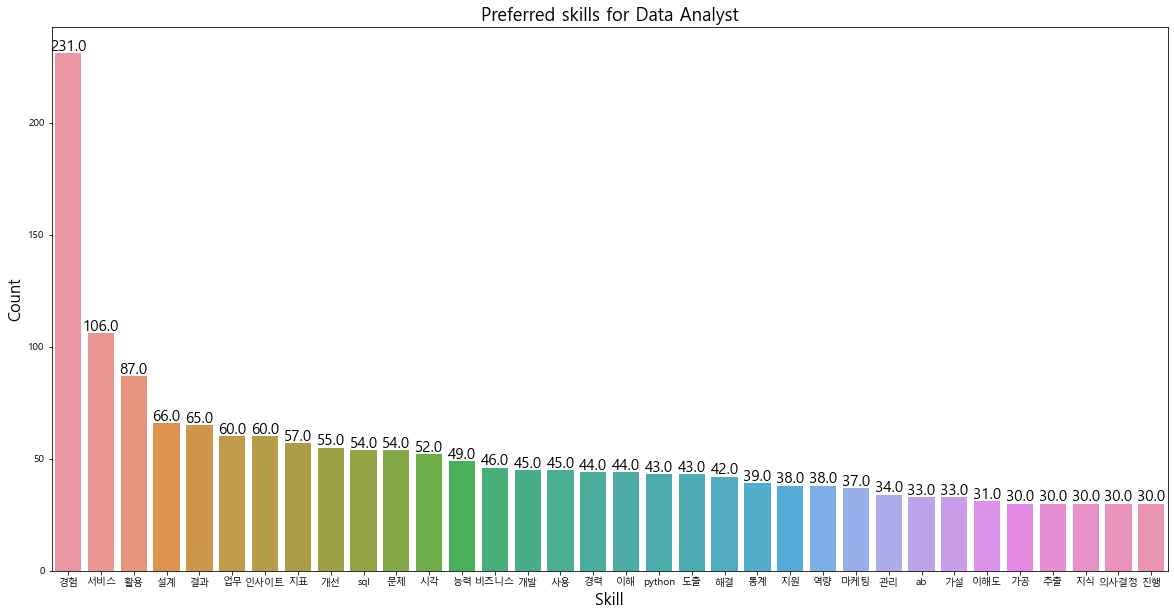
3. 분석
역시나 신입으로 취업하기 어려운 직무이다. 경력직 채용공고가 대다수인 만큼 '경험'이 압도적으로 빈출되었으며 상위 단어 모두 경험과 연관이 되어 있다. 신입이나 관련 경력으로 1년 이상을 요구하는 기업도 데이터를 직접적으로 다뤄서 문제를 해결하는 경험을 가장 우선시하는 것으로 분석된다.
'데이터 분석가는 무슨 일을 하나요?' 라는 질문에 위의 그래프에 나온 단어만 조합해도 대답할 수 있지 않을까 생각한다. 막연히 데이터를 통계적으로 분석해서 비즈니스에 도움을 주는 업무라고 생각했었지만 이 프로젝트를 통해 데이터분석가 업무와 요즘 회사에서 요구하는 skill, 관심있는 분석법을 파악할 수 있었다. 주말에 정기적으로 관련 키워드를 통해 데이터 직무 관련 지식을 갖추고 블로그에 정리해 나갈 예정이다.
'Jay's Project > wanted 채용 공고 분석' 카테고리의 다른 글
| [wanted 채용 공고 분석] 6. 기술 스택 분석(3) - 결과 분석 (0) | 2022.01.16 |
|---|---|
| [wanted 채용 공고 분석] 5. 기술 스택 분석(2) - 데이터 시각화 (0) | 2022.01.16 |
| [wanted 채용 공고 분석] 4. 기술 스택 분석(1) - 데이터 전처리 (0) | 2022.01.16 |
| [wanted 채용 공고 분석] 3. 데이터 수집(2) (0) | 2022.01.14 |
| [wanted 채용 공고 분석] 2. 데이터 수집(1) (0) | 2022.01.14 |