


이 프로젝트는 웹 사이트에서 데이터를 수집하므로 크롤링을 통해 데이터셋을 구축한다. 웹 사이트 크롤링이면 우선적으로 목표로 하는 웹 사이트의 구성을 살펴보고 접근 방법을 결정하는 것이 효율적이다.
본인도 이 프로젝트에서 마음이 앞서 무작정 크롤링이 시도하다가 스트레스만 받고 결과적으로 비효율적인 방식으로 시간을 허비하기도 했다.
채용 공고 크롤링을 위해 우선 원티드의 웹 화면 구성을 살펴보자
화면 구성 살펴보기
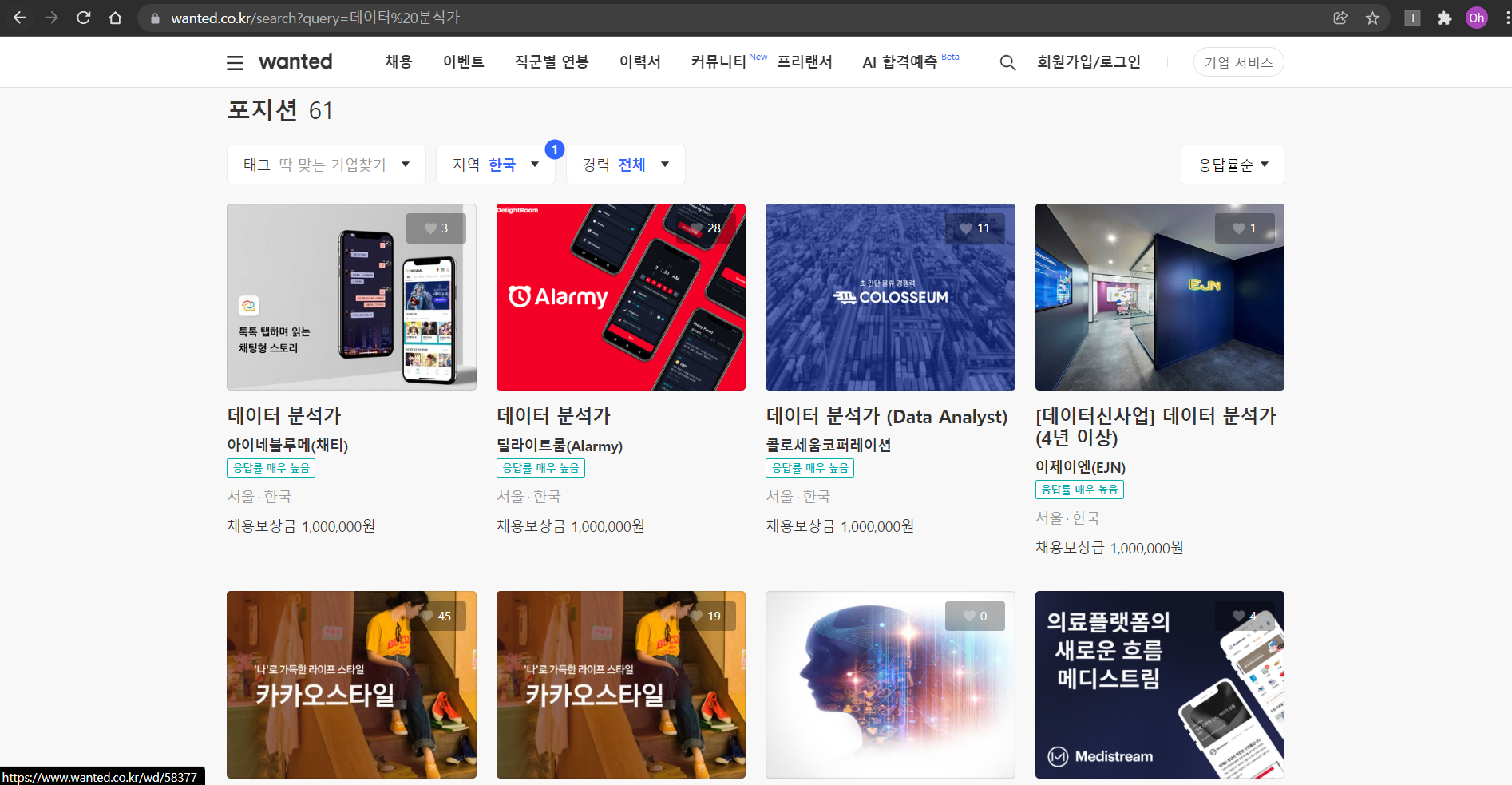
원티드 홈페이지에 접속하여 '데이터 분석가'로 검색한 결과이다. 61개의 포지션 채용 공고가 검색되었으며 한 줄에 4개씩 채용공고 타이틀, 회사명, 지역, 그리고 오른쪽 상단의 하트표시로 구직자가 찍어놓은 관심 수를 보여준다.
이제 구체적으로 수집하고 싶은 목표데이터에 접근하는 방법을 생각해보자
어떤 방식으로 데이터를 수집할 것인가?
먼저 해당 화면의 URL이 원티드 기본 URL에 /search?query임을 알 수 있다.
이는 검색결과를 Query parameter로 받는 형식으로 가장 접근하기 쉬운 형태이다.
검색 창에 키워드를 입력하고 검색 버튼을 누르는 과정을 생략하고 바로 쿼리형식에 '데이터 분석가'를 넣으면 해당 페이지로 이동할 수 있기 떄문이다.
만약 쿼리문으로 받는 형태가 아니라면 검색 창을 누르고 검색어를 입력하고 검색 버튼을 누르는 과정을 코딩으로 구현해야 한다.
원하는 데이터에 접근하기
2.1 개별 공고의 url (링크)
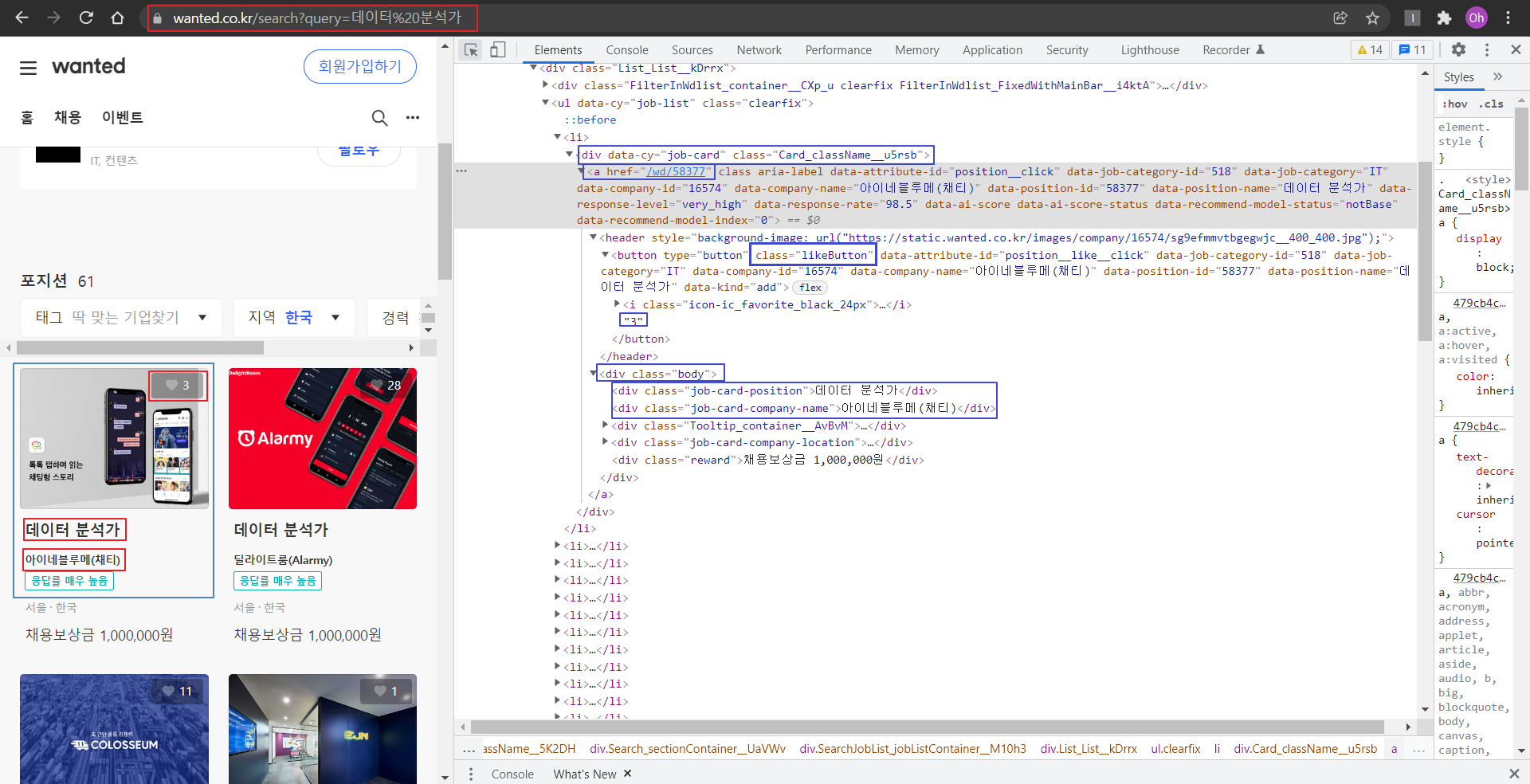
- 개별 공고를 클릭하면 a 태그의 href 값으로 이동한다
- 태그의 url 형태는 앞서 살펴본 쿼리 형식과 다르게 58322라는 숫자로 이루어져 있으므로 직관적인 규칙이 없다.
- 그러므로 다음의 코드를 이용해 전체 61개의 공고들의 세부 url을 전부 가져온 뒤 링크 정보만 추출한다.
import sys
import os
import pandas as pd
import numpy as np
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import chromedriver_autoinstaller
import time
from tqdm import tqdm_notebook
# 워닝 무시
import warnings
warnings.filterwarnings('ignore')# 각 공고의 url 가져오기
urls = '.Card_className__u5rsb > a'
url_raw = driver.find_elements_by_css_selector(urls)
# url만 가져오기
url_list=[]
for url in url_raw:
url = url.get_attribute('href')
url_list.append(url)
print(url_list[0])
print('url 갯수 :',len(url_list))2.2 채용공고 타이틀(포지션)
- body 클래스 안에 job-card-position 클래스로 지정되어 있으며 카든 뉴스 형태의 채용 공고 타이틀을 말한다.
- find_elements_css_selecter 코드를 이용해 전체 포지션을 selenium 리스트로 가져온 뒤 position_raw 변수로 지정한다.
- selenium 으로 구성된 타이틀을 text 언어로 변환하여 다시 position_list 항목에 넣는다.
# 채용공고 타이틀 가져오기
positions = '.job-card-position'
position_raw= driver.find_elements_by_css_selector(positions)
# 채용공고 타이틀 text 변환
position_list = []
for position in position_raw:
position = position.text
position_list.append(position)
print(position_list[0])
print('postion 갯수 :',len(position_list))2.3 회사명
- 위의 포지션과 동일한 과정으로 수집한다.
# 회사명 가져오기
names = '.job-card-company-name'
name_raw= driver.find_elements_by_css_selector(names)
# 회사명 text 변환
name_list = []
for name in name_raw:
name = name.text
name_list.append(name)
print(name_list[0])
print('name 갯수 :',len(name_list))
2.4 관심 수(텍스트)
- 별도로 class 이름이 likeButton으로 지정되어 있음을 알 수 있다. 수집 후 텍스트로 변환하면 네모친 숫자로 변환한다.
- 수집 후 관심 수를 기준으로 데이터를 나열하기 위해서는 str로 변환된 데이터를 다시 int형으로 변환해준다.
# 관심 수 가져오기
likes = '.likeButton'
like_raw= driver.find_elements_by_css_selector(likes)
# 관심 수 text 변환 후 int 변환
like_list = []
for like in like_raw:
like = int(like.text) # text로 변환 후 int로 자료형 변경 -> 추후 관심 수로 정렬하기 위함
like_list.append(like)
print(like_list[0])
print('관심 수 표시:',len(like_list))데이터프레임 구성
pandas 라이브러리로 수집된 데이트를 데이터프레임으로 변환하여 결측치나 빠진 항목이 없는 지 살펴본다.
df = pd.DataFrame({'url':url_list,'회사명':name_list,'타이틀':position_list,'관심':like_list})
df.style.set_properties(**{'background-color': 'yellow','text-align':'right'}) ## 오른쪽 정렬
df.head()
int로 변환한 관심 컬럼의 데이터를 기준으로 나열하여 관심 수가 많은 채용 공고가 무엇인 지 살펴 볼 수 있다.
df.sort_values('관심', ascending=False).head() # 관심 수로 정렬
정리
웹 크롤링에는 다양한 라이브러리를 이용할 수 있다. BeautifulSoap, Xml, parser를 이용한 방식 등 크롤링에 관한 정리는 이 포스팅에 정리해두었다.여기서는 selenium을 이용해 css selector 항목으로 주로 크롤링하였으며 개발자도구 창에서 알 수 있는 페이지 구성이 깔끔하게(?) 만들어져 비교적 손쉽게 목표 데이터를 수집할 수 있었다.
페이지 구성을 보면서 크롤링을 데이터 수집을 어떻게 할 것인가 결정해야 한다. 이 프로젝트에서도 데이터 수집 단계를 두 단계로 나누었다. 각 채용공고의 URL이 QUERY양식처럼 일정한 포맷으로 정해지지 않고 의미를 알 수 없는 숫자로 이루어져 있기 때문에 각각의 URL 들을 먼저 수집하고 이후에 수집된 URL로 다시 접근하는 방식을 택하였다. 사실 URL 정보만 수집해도 되었지만 실습 격 다른 항목도 수집해 보았다.
다음 포스팅에서는 수집된 URL에 접근하여 목표 데이터인 Job description을 구체적으로 수집해본다.
'Jay's Project > wanted 채용 공고 분석' 카테고리의 다른 글
| [wanted 채용 공고 분석] 5. 기술 스택 분석(2) - 데이터 시각화 (0) | 2022.01.16 |
|---|---|
| [wanted 채용 공고 분석] 4. 기술 스택 분석(1) - 데이터 전처리 (0) | 2022.01.16 |
| [wanted 채용 공고 분석] 3. 데이터 수집(2) (0) | 2022.01.14 |
| [wanted 채용 공고 분석] 1. 프로젝트 기획 (0) | 2022.01.13 |
| [wanted 채용 공고 분석] 0. 프롤로그 (1) | 2022.01.12 |