[Metacritic 포켓몬 S/S 리뷰 분석 프로젝트] 4. 데이터 시각화

데이터 수집과 전처리를 통해 본격적으로 시각화와 분석을 위한 데이터셋을 구축했다. 이번에는 파이썬 라이브러리를 통해 EDA와 시각화를 진행해본다.
이번 시각화에서는 matplotlib과 seaborn을 주로 사용하였으며 분석 파트에선 nltk를 이용한 분석을 진행하였다.
import matplotlib.pyplot as plt
import seaborn as sns
from nltk.stem.porter import PorterStemmer
from nltk.tokenize import wordpunct_tokenize
from nltk.corpus import stopwords
import nltk
nltk.download('punkt')데이터 시각화
Count plot
plt.figure(figsize=(20, 10))
all_count=sns.countplot(x='Grade',data=df_all,palette='Dark2')
all_count.set_title('Metacritic grade Count , Pokemon-S/S', fontsize=18)
all_count.set_xlabel('Grade', fontdict={'size':18}) # x축 이름
all_count.set_ylabel('Count', fontdict={'size':18})
for p in all_count.patches: # count 넣기
height = p.get_height()
all_count.text(p.get_x() + p.get_width() / 2., height + 3, height, ha = 'center', size = 15)
plt.show()

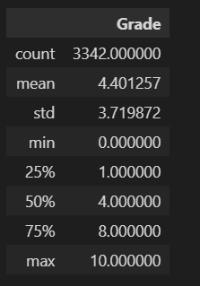
3342개의 리뷰 데이터의 평점을 나타낸 count plot 이다. count plot은 가장 기본적인 그래프지만 대략적인 분포를 시각적으로 파악하기 용이하다. 현재 0점이 가장 많고 다음은 10점이 뒤따르고 있다. 이를 통해 유저 평점이 극단적인 양상을 띄고 있음을 알 수 있다. 0점의 경우에는 본 작품의 불만 사항에 대해 극단적으로 표출된 유저들의 의견이라고 볼 수 있다. 뒤의 분석 파트에서 다시 살펴보겠지만 전작 포켓몬에 대한 개체 수 삭제 등 기존 작들과 차별화되는 부분에서 포덕들의 심기를 건드린 결과이다. 다음은 pie chart 를 통해 비율로 시각화해본다.
Pie chart
labels_sword = '0','10','3','1','2','4','9','8','5','6','7'
plt.figure(figsize=(7,7))
explode = [0.05, 0.05, 0.05, 0.05, 0.05, 0.05, 0.05, 0.05, 0.05, 0.05, 0.05]
wedgeprops={'width': 0.7, 'edgecolor': 'w', 'linewidth': 3}
# pie chart 만들기(차트 띄우기, labels 달기, 각 조정, 그림자, 값 소숫점 표시)
plt.pie(df_all['Grade'].value_counts(), startangle=45, shadow=True, labels = labels_sword ,autopct='%.1f%%',explode=explode,wedgeprops=wedgeprops)
# 라벨, 타이틀 달기
plt.title('Grade - Pokemon S/S', fontsize=18)
plt.legend(loc=(1.0,0.3))
plt.show()
Pie chart는 전체에서 특정 데이터가 차지하는 비율을 한눈에 볼 수 있다. matplotlib 라이브러리를 조금만 만지면 목적에 맞게 옵션을 조정할 수 있고 이쁘장하게 만들어 줄 수 있다. 현재 0점과 10점이 전체 평점 중 약 40%를 차지하고 있음을 알 수 있다.
Box plot
# 포켓몬 소드와 쉴드의 box plot 비교
plt.figure(figsize=(5, 5))
sns.set(style='ticks', palette = 'pastel') # style = "ticks", "whitegrid" / palette = "pastel", "Set3"
sns.boxplot(x='Grade', y="Game", palette=['b', 'r'], data=df_all)
plt.show()
box plot은 두 집단의 통계치를 비교하기에 용이하며 개별 데이터의 사분위수(quantile)와 이상값(outlier) 파악에도 활용할 수 있다. 위의 count plot과 pie chart는 소드와 실드를 구분하지 않고 한번에 시각화하였지만 box plot에서는 두 게임 간의 차이점을 보이는지 파악하는 목적으로 활용하였다.
포켓몬 실드가 소드에 비해 좀 더 넓은 분포를 가진 것을 알 수 있으며 중앙값의 경우에는 약 4점으로 두 게임 모두 동일하다. (0점~10점의 11개의 이산값 중의 중앙값이므로) 포켓몬 게임을 해 본 유저는 알겠지만 포켓몬스터 게임 타이틀은 두 가지 버전이 한번에 출시되며 등장 포켓몬과 npc들의 포켓몬이 조금씩 다를 뿐 기본 게임성은 거의 동일하다. 또한 box plot에서도 큰 차이를 보이지 않았으므로 t-test와 같은 통계 검정은 생략하였다.
데이터 분석 (Word Cloud)
EDA

긍정 리뷰 분석
df_pos = df_all[df_all['Grade']>=5] # grade 5점 이상은 긍정으로 분류
# 긍정 리뷰들 리스트로 변환
pos_list = df_pos['Review'].tolist()
len(pos_list)
# str 타입이 아닌 요소들이 있으면 전부 str 타입으로 바꾸기
for i in range(len(pos_list)):
if type(pos_list[i]) != str:
pos_list[i] = str(pos_list[i])
# 리스트 중 str 타입이 아닌 요소들(nan값)이 존재함을 확인
for i in pos_list:
if type(i) is not str:
i = str(i)
print(i)
# nltk 분해기로 단어 토큰화
stop = stopwords.words('english') # 토큰화 작업을 위한 리소스 다운로드
pos_word_tokens = [w for w in nltk.tokenize.word_tokenize(pos_content_text) if w not in stop]
len(pos_word_tokens)
# 불용어 사전 작성
stop_words = [',','0','game','pokemon','games','pokémon','even','really','much','would','also','get','like','good','great','fun','new','still','lot','people','think','pok','mon','one']
pos_word_tokens = [word for word in pos_word_tokens if not word in stop_words] #불용어 제거
pos_cleaned_counted=Counter(pos_word_tokens)
pos_cleaned_counted_ranked = dict(pos_cleaned_counted.most_common(300)) # 내림차순 정렬 후 딕셔너리화
pos_cleaned_counted_ranked# wordcloud 만들기
wc = WordCloud(font_path = 'C:\Windows\Fonts\malgun.ttf',background_color="white",width=2000, height=1000).generate_from_frequencies(pos_cleaned_counted_ranked) # font 경로 개별적으로 설정해야함
plt.figure(figsize = (40,40))
plt.imshow(wc)
plt.axis('off')
plt.show()
- 긍정 / 부정 분류 기준 : 현재 데이터를 두 집단으로 나누기위해 중앙값을 사용한 것 (5~6점은 긍정리뷰가 아니다)
- 불용어 처리 : 명사만 추출하고 불용어 사전 작성에 조금 더 심혈을 기울였어야 했다.
부정 리뷰 분석
stop_words = [',','0','game','pokemon','games','pokémon','even','really','much','would','also','get','bad','many','could','make','still','someone','look','go','new','first','moves','every','feels','lot','made','feel','every','like','pok','mon','way','one','good']
neg_word_tokens = [word for word in neg_word_tokens if not word in stop_words] #불용어 제거
neg_cleaned_counted=Counter(neg_word_tokens)
neg_cleaned_counted_ranked = dict(neg_cleaned_counted.most_common(300)) # 내림차순 정렬 후 딕셔너리화
neg_cleaned_counted_ranked
jaydatum - Overview
Data analyst / scientist. jaydatum has 11 repositories available. Follow their code on GitHub.
github.com